Live Migration: Paying for the Sizzle
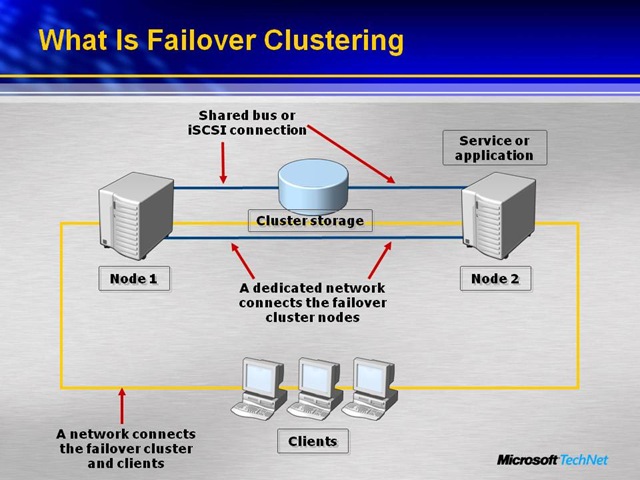
Study the graphic closely and you’ll notice the secret but costly component that makes Live Migration function so well. People often confuse Azure Site Recovery or replicated offline copies of virtual servers with moving virtual servers to another physical host – while running with no impact on users.
The innocuous cluster storage is what most businesspeople don’t recognize as a critical part of the real magic. Since 2012, Microsoft’s Hyper-v failover clustering has allowed you to have two or more physical servers (Node 1 and Node 2), using shared storage which is where the virtual servers actually reside. The virtual servers don’t really move, as the failover software simply hands control off from one node to another.
The problem is that the required Storage Area Network (SAN) for the cluster storage is generally 2x – 3x the cost of the physical servers alone. Let’s say $35,000 to be conservative. Then a moderately complex separate network is also required with at least two dedicated switches. By the way, it’s recommended to buy two of whatever storage you pick to avoid a single point of failure with added firewall configuration for another site. Finally, the 4 – 5 year hardware warranty means you’re forced to upgrade or replace storage that often to maintain support.
Typical scenario. Today, we generally setup two Hyper-v nodes, load balance virtual servers, and add online backup and disaster recovery. Each node has redundant disks, power, and networking. The equipment comes with a 4 hour guaranteed response for parts replacement 24×7 from the manufacturer. The whole goal is to recover from major equipment failure to total loss of facilities in 8 – 24 hours.
Invariably, some customers hear such numbers and think that is a long time. For most medium business customers, the reality is that it is not cost-effective to implement computer systems with high availability above 99% uptime or 3.65 days of downtime per year. That roughly equates to a weekly maintenance window of approximately 1.5 hours, often at night or on weekends outside of normal business hours.
High availability. However, some customers are committed to trying to achieve four nines (99.99%) of uptime or just under 5 minutes of downtime per month. As shown by Microsoft’s Rob Waggonner below, there is no doubt that the technology is slick. Network administrators can move running machines around in just a few seconds, shutdown a physical server for maintenance or upgrade, and not impact the users. Unfortunately for shareholders, this capability means a huge waterfall effect of double the hardware and software – along with added staff or services for maintenance.
Then the negotiation starts and virtualization blunders happen. Maybe we don’t need storage, or any redundancy in equipment, and who will know the failover doesn’t work? To maintain true high availability, you simply can’t cut corners and must understand the upfront and ongoing costs. Although this approach is only a few years old, there are better ways to streamline your technology.